강의 : 유데미 - 머신 러닝 & AI 로 추천 시스템 구축하기
1. 정확도 매트릭
1-1) MAE

1-2) RMSE

2. Top-N 적중률 (hit rate)
hit rate : 정답이 얼마나 Top-N에 포함되었는가? (위치 고려 안함)
2-1. leave-one-out cross validation
훈련 데이터 속 각각의 사용자에 대해 순위추천을 계산하고 의도적으로 그사용자의훈련 데이터 중 한 항목 제외
-> 추천시스템이 시험단계에서 사용자를 위해 생성한 순위 결과 속 제외된 항목을 추천할 수 있는지
2-2. average reciprocal hit rate (ARHR)

추천리스트 (Top-N) 안에 정답(실제로 사용자가 좋아한 아이템)이 있다면 그 위치(rank)의 역수(1/rank)를 점수로 부여해서 평균낸 것
● 계산 방식
1) 각 사용자에 대해 추천 리스트를 만들고
2) 리스트 안에 정답 아이템이 있다면 -> 그 순위를 rank 라고 했을 때 점수는 1/rank
3) 모든 사용자에 대해 위 점수를 평균냄
● 예시 (gpt 참고)
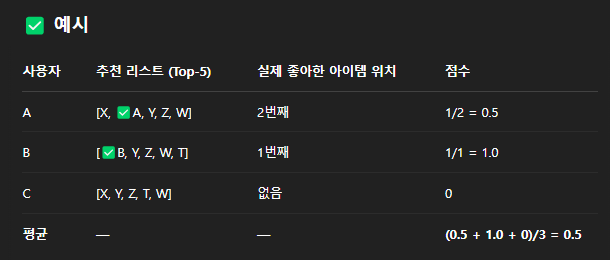
● 중요한 이유
- 리스트 상단에 정답이 있을수록 높은 점수
- 사용자들은 주로 위쪽 추천만 보기 때문에 현실적인 평가 방법
2-3. cumulative hit rate (cHR, 누적 적중률)
● hit rate에서 특정 조건(ex_평점이 일정 기준 이상인 경우만)을 만족하는 경우에만 적중으로 인정하는 평가지표
● 정말로 좋아한 항목에만 적중했는지 보는 방식
● 예 : 평점 기준 3
| hit rank | predicted (or actual) rating |
| 4 | 5.0 |
| 1 | 5.0 |
- 사용자별로 추천 리스트 생성
- 각 추천 리스트에서 실제로 사용자가 **좋아한 아이템(예: 평점 ≥ 4)**만을 대상으로 적중 여부 확인
- 적중한 사용자 수 / 전체 사용자 수 → 이것이 Cumulative Hit Rate
2-4. rating hit rate (rHR, 평점 적중률)
● 추천된 아이템들 중에서, 실제로 평점이 높은 아이템이 얼마나 있는지를 평가하는 지표
● 추천 리스트가 진짜로 사용자가 좋아하는 항목들로 채워졌는지 측정
● 계산 방식
1) 사용자에게 Top-N 추천 리스트를 생성
2) 그 리스트 안에서 실제 평점이 기준 이상인 항목만 Hit으로 간주
3) rHR = (리스트 내 고평점 항목 수)/(Top-N 전체 추천 수)
| 추천된 항목 | 실제 평점 |
| A | 5 |
| B | 2 |
| C | 4 |
| D | 3 |
| E | 1 |
- 평점 기준 : 4점 이상
- 고평점 항목 : A, C (2개)
- 전체 추천 수 : 5개 -> rHR = 2/5 = 0.4 (40%)
3. 적용 범위의 다양성과 참신함
추천시스템은 정확성 뿐만 아니라 제공률 + 다양성 + 참신성 + 신뢰성 사이의 균형이 핵심!
3-1. 제공률 (Coverage)
% of <user, item> pairs that can be predicted- 추천 가능한 전체 항목 중 얼마나 많은 항목을 추천할 수 있는지
- 높을수록 다양한 항목에 대한 추천이 가능
- 정확도와 트레이드오프 관계
3-2. 다양성 (Diversity)
1-S- 추천 리스트 내 항목 간의 유사도가 낮을수록 다양성이 높음
- 계산: 1 - 평균 유사도
- 너무 높으면 엉뚱한 추천 가능성도 → 균형 필요
3-3. 참신성 (Novelty)
mean popularity rank of recommended items
- 얼마나 대중적이지 않은 항목을 추천하는가
- 롱테일 제품 추천과 연결됨 (추천시스템의 핵심은 롱테일 전략으로 데이터를 제공하는 것)
- 지나치면 사용자 신뢰 저하 가능 (사용자 신뢰 : 익숙한/대중적인 항목도 일정 부분 포함해 신뢰가 형성됨. 신뢰가 기반되어야 참신한 항목도 수용이 가능해짐)
4. 이탈 응답성 및 A/B 테스트
4-1. 이탈률 (Churn)
how often do recommendations change?
- qg추천 목록이 얼마나 자주 바뀌는가를 측정
- 너무 안 바뀌면 추천이 지루하고,
너무 자주 바뀌면 신뢰 저하 위험 - 변화에 민감하지만 무작위 추천은 지양
4-2. 민감성 (Responsiveness)
how quickly does new user behavior influence your recommendations?
- 사용자의 새로운 행동에 얼마나 빨리 반응하는가
- 민감성이 너무 높으면 시스템이 복잡해지고 유지 비용 증가
- 사업 목적에 맞게 적정 수준 유지 필요
4-3. 온라인 A/B 테스트
- 실제 사용자 행동을 기준으로 추천 시스템을 평가
- 추천 리스트에 대한 클릭률, 구매율, 반응률 측정
- 현실에서 가장 신뢰할 수 있는 평가 방법
4-4. 지각 품질 평가 (Perceived Quality)
- 사용자에게 직접 *이 추천이 좋았나요?"라고 묻는 방식
- 문제점: 사용자가 아이템 품질과 추천 품질을 혼동할 수 있음
대리 문제 (Proxy Problem)
- 우리가 진짜로 원하는 목표를 직접 측정하기 어려우니 대신 다룰 수 있는 수치를 대리로 사용하는 것
추천시스템에서 좋은 추천은 정량적인 지표만으로는 설명하기 어려움.
사람마다 좋은 추천의 기준이 다르고, 문화, 취향, 맥락에 따라 반응이 달라지기 때문에
무슨 지표를 사용해 평가할지 결정하는 자체가 예술적 감각이 필요한 일
5.